


DeepSeek will unleash a wave of AI innovation
It's leveling the playing field, upending the business model of the big established players.

Introduction
DeepSeek R1, the latest AI (and first ‘reasoning’) model developed by High-Flyer, a quantitative hedge fund based in Hangzhou, China is run by AI hobbyist Liang Wenfeng, the founder and CEO of DeepSeek.
R1 has caused a sudden stir. It’s certainly not the first AI model by High-Flyer, the company has amassed a group of very well-paid nerds that, due to restrictions, were forced to do more with less and at first sight succeeded spectacularly.
Instead of brute force used by most Western AI developers building Manhattan-sized AI data centers, DeepSeek had to work with modest resources due to restrictions and budget. That approach has paid off.
The ramifications for the industry are manifold, we will argue that:
DeepSeek has upended the already questionable business model advancement through ever bigger (‘Manhattan-sized’) data centers by being able to do more with less, introducing significant innovations that save on resources and data, and offering API services at a fraction of the cost of existing players, destroying their pricing power.
More importantly still, by being open source, it opens up the field for others to experiment with their models, multiplying points of innovation which will quickly erode or emulate any advancement coming from the established players, further undermining their business models.
In essence, it’s reducing barriers to entry, leveling the playing field, thereby democratizing AI development.
History
DeepSeek is a new player, the brainchild of a 40-year-old AI enthusiast Liang Wenfeng, the CEO of Hong Kong hedge fund High-Flyer which assembled a (well-paid) geek squad and self-funded an artificial general intelligence lab in April 2023, which became DeepSeek in May 2023.
They made rapid progress having to do more with less as a result of restrictions, ultimately leading to the release of R1, its first reasoning model, that is causing quite a stir.
Is R1 any good?
Well, yes. It’s comparable (see here and here) to the first reasoning model from Open AI, the o1 model. Here is Analytics Vidhya (our emphasis):
DeepSeek models have consistently demonstrated reliable benchmarking, and the R1 model upholds this reputation. DeepSeek R1 is well-positioned as a rival to OpenAI o1 and other leading models with proven performance metrics and strong alignment with chat preferences. The distilled models, like Qwen 32B and Llama 33.7B, also deliver impressive benchmarks, outperforming competitors in similar-size categories.
More on these distilled models below, but here is a distilled version of the comparison:

It’s certainly been good enough to amaze a whole host of industry insiders, from Ars Technica:
On Monday, Altman tweeted, "deepseek's r1 is an impressive model, particularly around what they're able to deliver for the price.
Marc Andreessen even spoke of a ‘Sputnik moment’ calling DeepSeek R1:
one of the most amazing and impressive breakthroughs I’ve ever seen – and as open source, a profound gift to the world
How efficient is it?
The parent company is an AI-based hedge fund that isn’t known to have AI-server farms in the billions, let alone tens of billions, and they also had to make do with the less efficient H800 chips from Nvidia (until these fell onto the export ban as well).
Here is eetimes (our emphasis):
AI-driven Chinese hedge fund High-Flyer AI, trained V3 on an extremely modest cluster of 2,048 Nvidia H800 GPUs. The H800 is a cut-down version of the market-leading H100 for the Chinese market, which was designed to skirt the U.S. export regulations at the time. The H800s are compute capped and have reduced chip-to-chip communication bandwidth, which is vital for training LLMs. For V3, a 671B MoE model that activates about 37B parameters on each forward pass, DeepSeek’s paper says they used 2.788 million GPU hours to pre-train on 14.8 trillion tokens. On their cluster of 2,048 GPUs, that would have taken 56 days, and at $2 per GPU-hour, the cost is estimated at $5.5 million. This figure is for the pre-training stage of V3 only.
V3 was the previous version of the R1 model that caused such a stir. The $5.5M is just for the pre-training stage, which the article estimates about a factor of 10 cheaper than Llama 3.1-405B. OpenAI’s GPT-4 reportedly cost $100M to train.
There are of course several other costs:
It should be noted that the $5.5 million figure is projected (not a real dollar spend) for one training run, one time. Development of the V3 model surely took months or years of expensive research and development, including failed training runs that are not counted here. The cost of compute used for further reinforcement learning and supervised fine-tuning (plus the cost of developing or obtaining synthetic data for this, see below) to make V3 into R1 are also not counted, and were probably considerable.
But that holds for the other models as well so given what we know, we think it’s likely that R1 is significantly more efficient than other models, perhaps in the realm of an order of magnitude. There is other corroborating evidence, from Techspot (our emphasis):
An earlier version of DeepSeek also triggered an intense price war in China back in May. DeepSeek-V2's incredibly low cost of just 1 yuan (14 cents) per million tokens of data processed forced major cloud providers like Alibaba to slash their own AI model pricing by up to 97%.
While the exact figures about how much cheaper it was to develop R1 are difficult and at least somewhat contentious, the fact that the company developing it isn’t known to have access to data centers in the tens of billions, had to make do with export restrictions, and applied a host of creative approaches to do more with less makes it very plausible they did develop in a very cost-efficient way using much less resources.
Western AI model builders seem to take it very seriously. Meta has opened 4 war rooms to reverse engineer R1.
One might add that these creative approaches deployed by the company are out there as R1 is an open-source model and the company wrote a research paper describing these (and even describing which approach didn’t deliver).
How does it achieve its efficiency?
The company was remarkably open about its innovations, publishing these in a release paper that even discussed the approach that didn’t work.
The above-cited EETimes article (as well as a Techradar article) mentions various tricks, like:
One of the biggest seems to be DualPipe, a parallel-pipelining algorithm they invented, which successfully overlaps compute and communication in such a way that most of the communication overhead is hidden... The company also developed all-to-all communication kernels (at the PTX level, a level below CUDA code) that better utilize Infiniband and NVLink bandwidth, and tinkered with the memory footprint to avoid having to use tensor parallelism at all. The net result is to hide communication bottlenecks. The company also dropped precision to FP8 in as many places as possible, among other techniques.
DeepSeek had other tricks up their sleeve which we won’t go into in great detail (this is not supposed to be a technical paper) but we provide the sources for those interested:
DeepSeekMoE (see here).
Initially using reinforcement learning only which produced the R1-Zero model (here, here, here, and here), only then combining it with supervised fine-tuning (producing the R1 model).
Great sources discussing and explaining these are AnalyticsVidhya, Datacamp, and Huggingface. The latter took the model apart in their Open-R1-project order to:
systematically reconstruct DeepSeek-R1’s data and training pipeline, validate its claims, and push the boundaries of open reasoning models
Speaking about the predecessor V3 model, they argued:
What’s especially impressive is how cost-efficient it was to train—just $5.5M—thanks to architectural changes like Multi Token Prediction (MTP), Multi-Head Latent Attention (MLA) and a LOT (seriously, a lot) of hardware optimization.
AnalyticsVidhya concludes
Beyond its impressive technical capabilities, DeepSeek R1 offers key features that make it a top choice for businesses and developers:
Open Weights & MIT License: Fully open and commercially usable, giving businesses the flexibility to build without licensing constraints.
Distilled Models: Smaller, fine-tuned versions (akin to Qwen and Llama), providing exceptional performance while maintaining efficiency for diverse applications.
API Access: Easily accessible via API or directly on their platform—for free!
Cost-Effectiveness: A fraction of the cost compared to other leading AI models, making advanced AI more accessible than ever.
DeepSeek R1 raises an exciting question—are we witnessing the dawn of a new AI era where small teams with big ideas can disrupt the industry and outperform billion-dollar giants? As the AI landscape evolves, DeepSeek’s success highlights that innovation, efficiency, and adaptability can be just as powerful as sheer financial might.
Distillation
Readers might have spotted that, after initially being very impressed, Open AI accused DeepSeek of using its models through a process known as distillation (making smaller LLMs more efficient by training them to copy outputs of bigger LLMs). Distillation is prohibited by OpenAI’s terms of use, but xAI’s Grok has also used distillation, allegedly. Distillation saves greatly on training cost, here is the Algoritmic Bridge:
A R1-distilled Qwen-14B—which is a 14 billion parameter model, 12x smaller than GPT-3 from 2020—is as good as OpenAI o1-mini and much better than GPT-4o or Claude Sonnet 3.5, the best non-reasoning models. That’s incredible. Distillation improves weak models so much that it makes no sense to post-train them ever again. Just go mine your large model. And without increasing inference costs.
The author argues that Open AI also uses distillation, albeit with their own model:
The fact that the R1-distilled models are much better than the original ones is further evidence in favor of my hypothesis: GPT-5 exists and is being used internally for distillation.
Analytics Vidhya noted that the High-Flyer has created much smaller distilled versions that are very good:
Another game-changing approach used by DeepSeek was the distillation of reasoning capabilities from the larger R1 models into smaller models, such as:
Qwen, Llama, etc. By distilling knowledge, they were able to create smaller models (e.g., 14B) that outperform even some state-of-the-art (SOTA) models like QwQ-32B. This process essentially transferred high-level reasoning capabilities to smaller architectures, making them highly efficient without sacrificing much accuracy.
One of these even managed to run on a Raspberry Pi.
If you’re interested in these much smaller distilled models, they are described here. Overall, we think that The Turing Post summed it up well:
one of the most exciting examples of curiosity-driven research in AI… unlike many others racing to beat benchmarks, DeepSeek pivoted to addressing specific challenges, fostering innovation that extended beyond conventional metrics.
Data efficiency
There is another, underappreciated benefit of DeepSeek’s approach (Fortune, our emphasis):
Beyond being “compute-efficient” and using a relatively small model (derived from larger ones), however, DeepSeek’s approach is data-efficient. DeepSeek engineers collected and curated a training dataset consisting of “only” 800,000 examples (600,000 reasoning-related answers), demonstrating how to transform any large language model into a reasoning model. Anthropic’s Jack Clark called this “the most underhyped part of this [DeepSeek model] release.” Then a Hong Kong University of Science and Technology team announced it replicated the DeepSeek model with only 8,000 examples. There you have it: we are off to the races, specifically starting a new AI race—the Small Data competition.
Note also how this was immediately improved upon by the team at the Hong Kong University of Science and Technology, another crucial element undermining the business model of the big AI players (see below).
Pricing
From AnalyticsVidhya:
Here’s a cost comparison:
DeepSeek R1 API: 55 Cents for input, $2.19 for output ( 1 million tokens)
OpenAI o1 API: $15 for input, $60 for output ( 1 million tokens)
API is 96.4% cheaper than chatgpt.
From Statista:
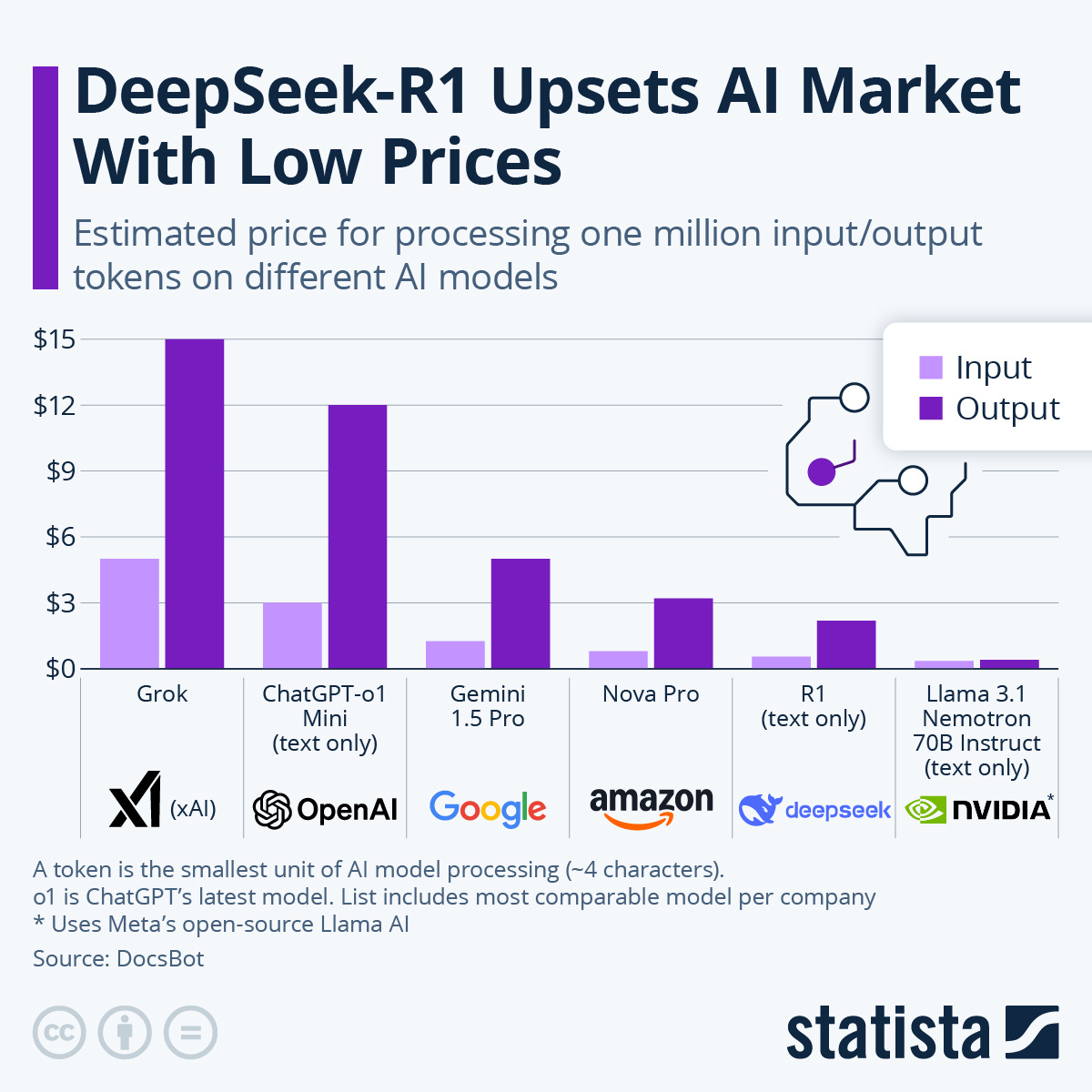
It’s way cheaper than Open AI’s o1 (and that’s the mini version in the graph, the full version is more expensive) let alone xAI’s Grok, although it’s not the cheapest, which is Llama 3.1 from Nvidia itself, which can afford to offer cheap models and while good, it’s not a reasoning model.
Reaction
From CNN (our emphasis):
“All those other frontier model labs — OpenAI, Anthropic, Google — are going to build far more efficient models based on what they’re learning from DeepSeek,” said Gil Luria, head of technology research at investment firm D.A. Davidson. “And you’ll be able to use those at a fraction of the price that you can now, because it’s going to be a fraction of the cost to run those models.”... “The paradigm is shifting,” said Zack Kass, an AI consultant and former OpenAI go-to-market lead. “It’s so hard to own a scientific breakthrough” such as an AI model advancement, Kass said, and prevent competitors from catching up. Instead, tech companies may now find themselves competing to lower costs and build more helpful applications for consumers and corporate customers — and also to suck up less power and natural resources in the process.
From eetimes (our emphasis):
No doubt the big U.S. AI labs are working hard to replicate and implement similar techniques as we speak.
Meta opened four war rooms to reverse engineer DeepSeek’s efficiency methods.
Microsoft and Perplexity are using it.
Open AI is seriously considering becoming open source again, and also this:
Altman said that R1's launch had pushed OpenAI to display its models' reasoning. While DeepSeek's (DEEPSEEK) R1 reveals its entire chain of thought, OpenAI's models conceal their reasoning in order to prevent competitors from scraping data.
Do we need Manhattan-sized AI-server farms?
We wondered about this even before the advent of R1, given that these datacenters have significant running cost and huge depreciation rates, and given that LLMs are a relatively new phenomenon, that usually means there are multiple open paths to significant improvement rather than using brute force alone. Indeed, that’s exactly what Andrej Karpathy who co-founded OpenAI, posted on X:
Does this mean you don't need large GPU clusters for frontier LLMs? No, but you have to ensure that you're not wasteful with what you have, and this looks like a nice demonstration that there's still a lot to get through with both data and algorithms.
Open Source
DeepSeek’s R1 model is an open source model available (from the AI dev platform Hugging Face) under an MIT license, meaning it can be used commercially without restrictions.
That is, everybody can use it, experiment, alter it, improve on it and change it as they see fit. This is already happening on a massive basis, from Techcrunch (our emphasis):
Clem Delangue, the CEO of Hugging Face, said in a post on X on Monday that developers on the platform have created more than 500 “derivative” models of R1 that have racked up 2.5 million downloads combined — five times the number of downloads the official R1 has gotten.
This was Monday the 27th of January, hardly a week since the appearance of DeepSeek R1.
Basically what DeepSeek has done is leveling the playing field, massively lowering the barriers of entry and multiplying the possible sources for the next breakthrough, which no longer necessarily have to depend on data centers the size of Manhattan.
Jevons paradox
Still, one could argue that making AI cheaper and more efficient, it’s use will increase, a phenomenon known as the Jevons paradox. However
I liked this balanced view from The Economist, which argues that a full Jevons effect is very rare and depends on whether price is the main barrier to adoption. With only “5% of American firms currently using AI and 7% planning to adopt it”, Jevons’ effect will probably be low. Many businesses still find AI integration difficult or unnecessary.
The jury is still out on this, but the significance of DeepSeek lies elsewhere.
DeepSeek has upended the Gen AI business model
We always questioned how the big AI companies could justify spending tens of billions of dollars on massive AI-server farms the size of Manhattan. What’s the business model, taking into consideration the energy bills (and often separate investments in energy supply needed) and the steep depreciation of these huge CapEx projects.
Yes, sure, it’s a general-purpose technology that can achieve amazing things, but somewhere down the line these enormous investments must make a return, and generate a revenue stream.
And it’s here that DeepSeek has done the greatest damage, it’s upending an already very questionable business model by:
Greatly undercutting most existing models on price while being comparable in quality, seriously altering the economic returns and destroying pricing power. They already did the same in China’s home market and is it a coincidence that both Microsoft (with ChatGTP+ which is Open AI o1 model and was $20/m subscription) and Open AI itself with its newest reasoning model o3 is making access free (albeit with restrictions on use)? They are forced to.
Showing that brute force doesn’t necessarily win, doing more with less can lead to comparable results and one shouldn’t be surprised existing players starting to take that approach more seriously in their own model developments.
Producing distilled models that are very good and run on a fraction of the resources of the big models, reducing the dependence on big data centers further.
Spilling the beans by its open-source approach. If not on price, the only way existing models can compete is to produce much better models, whether through brute force, ingenuity, or a combination of both. But DeepSeek has upended this as well as they:
Are able to match performance within weeks or months (at a fraction of the cost),
More importantly still, it’s empowering any AI lab to be creative by spilling the beans, it’s democratizing AI development, greatly reducing the barriers to entry, and leveling the playing field. Innovations will likely come from many more sources.
So R1’s efficiency is not the only, or even the most important factor here. It’s open source, that is, everybody can use it and improve on it as they see fit. And guess what,
Microsoft and Perplexity are already doing just that and in the first week since its appearance, developers on the platform have created more than 500 “derivative” models of R1 that have racked up 2.5M downloads combined
Cerebras, which we flagged as one of the most serious Nvidia competitors, is offering blisteringly fast access to DeepSeek with the use of its wafer-scale AI chips housed on US servers so no worries about Chinese access to data. (see Venturebeat).
If everybody has access to efficient cheap (free!) AI models, which they can use and improve upon as they see fit, why pay for an expensive one?
If any competitive advantage newer models may have is only very temporary, and if innovation will come from many more sources, what’s the business model of the big ‘Manhattan-sized’ server farms being built, how does one generate a return on that?
Conclusion
Not all of this is new, there are other open source models, other Mix-of-Expert models, and distillation isn’t invented by DeepSeek, for instance. But the combination of quality, price, efficiency, and open source is upending the business model of established AI players relying on ever bigger data centers and swings the pendulum towards doing more with less, opening the floodgates of innovation from many more sources, leveling the playing field.
Soo, OpenAI's DeepResearch, which just arrived has been cloned by a team of geeks at Hugging Face https://www.tomsguide.com/ai/chatgpts-powerful-deep-research-upgrade-got-an-open-source-replica-in-just-24-hours We wonder with cheaper models like DeepSeek arriving and advances being matched by others, what is the ROI for the big AI companies, given that these server farms costs tens of billions of dollars, run up huge energy bills and depreciate in 3-4 years?